






WordPress開発分野において、データストレージソリューションの選択は基礎的かつ重要なアーキテクチャ上の決定事項であり、約60%のパフォーマンス最適化コストと85%のデータ移行複雑度に直接影響する。wp_postmetaプラットフォームに組み込まれたメタデータ管理システムとして、90%プラグインを超える拡張データを格納するテーブルと、独自設計のストレージソリューションであるカスタムデータテーブルは、二つの全く異なる設計哲学と技術的アプローチを体現している。業界データによれば、誤った選択はプロジェクト中期における再構築率を35%まで上昇させ、平均140工時のメンテナンスコスト増加をもたらす。
それらの本質的な特性、性能表現、および適用範囲を理解することは、開発者がプロジェクトの初期段階で合理的なアーキテクチャ選択を行い、技術的負債の蓄積による後期の保守困難を回避するのに役立ちます。これにより、データクエリ効率の差を最大20倍の範囲内に抑えることが可能です。

一、アーキテクチャの本質と設計哲学の差異
1.1 wp_postmeta:柔軟性を優先したEAVモデル
ワードプレスwp_postmetaテーブルはエンティティ-アトリビュート-値(EAV)という古典的な設計パターンを採用している。その核心的な考え方は、データ構造自体もデータの一部として保存することであり、データベース設計段階で固定化しないことである。
技術的な実装レベルでは、各メタデータレコードは4つの基本構成要素を含む:一意の識別子、関連する記事ID、属性名文字列、および対応する属性値。すべての値はプレーンテキスト形式で保存され、システムはその具体的なタイプを解釈するためにアプリケーション層のロジックに依存する。
この設計がもたらす最大の利点は拡張の容易さです。記事に新しい属性を追加する必要がある場合、開発者はデータベース構造を変更する必要がなく、コード内で新しい属性名を使用するだけで済みます。このゼロモード変更の特性により、プラグインやテーマは複雑な移行操作を必要とせず、WordPressのコアデータモデルを容易に拡張できます。
柔軟性の代償は型安全性の欠如である。すべての値がテキスト形式で保存されるため、データベースはデータ型に対する制約を適用できず、データ検証の責任は完全にアプリケーションコードに移行する。これによりデータ不整合のリスクが高まり、値ベースのクエリ操作の効率も低下する。
1.2 カスタムデータテーブル:構造優先の正規化設計
カスタムデータテーブルは従来のリレーショナルデータベース設計手法を採用している。開発者は設計段階でテーブル構造を明確に定義し、各フィールドの名前、データ型、制約条件、およびテーブル間の関係を明示する。
このパラダイム化された設計の核心的な強みは、データの完全性と一貫性にある。データベースエンジンはストレージレベルでデータ型チェックや外部キー制約などの検証を実行し、データの正確性を保証する。フィールドには明確な意味と型が定義されているため、クエリ最適化器は効率的な実行計画を生成できる。
カスタムテーブルの設計では、開発者はプロジェクト初期段階でデータ構造を明確に理解する必要があります。後から移行操作でテーブル構造を変更することは可能ですが、単純に新しいメタデータ属性を追加するよりもはるかに複雑です。この初期投資により、後期のクエリパフォーマンスが大幅に向上し、データ管理の標準化が実現されます。
二、検索効率と性能の客観的分析
2.1 簡易クエリシナリオにおけるパフォーマンス
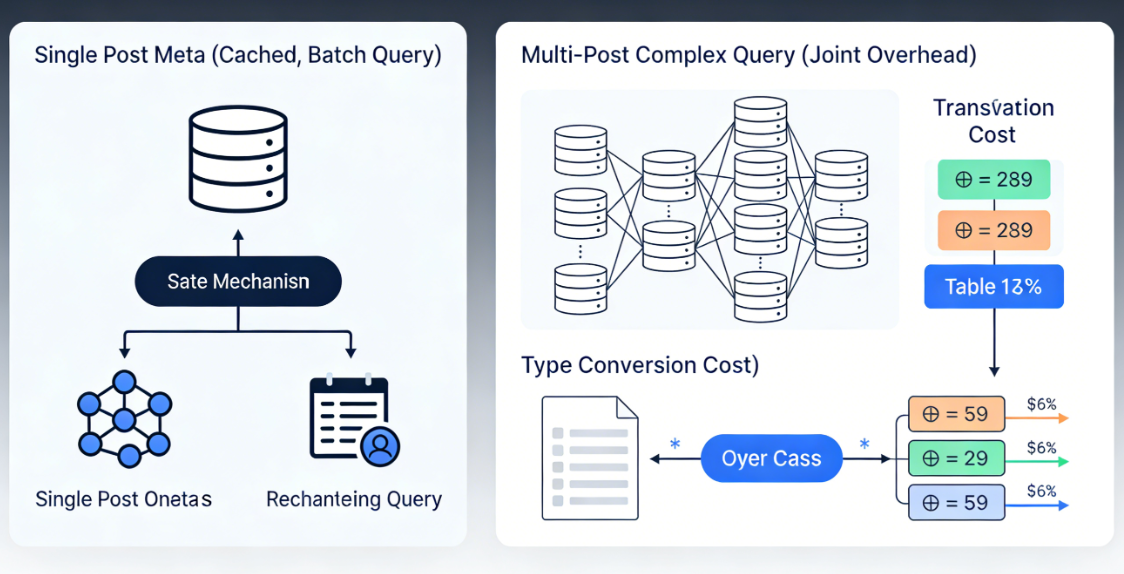
単一の記事に基づくメタデータ操作については、wp_postmeta最適化後の表は許容できる性能を提供できる。ワードプレス内蔵のキャッシュ機構は最近クエリされたメタデータを保存し、データベースへの直接アクセスを減らします。記事の全メタデータを取得する必要がある場合、システムは関連する全レコードを取得するクエリを一度実行します。このバッチ処理方式は、ある程度パフォーマンス負荷を軽減します。
しかし、複数の記事や複雑なフィルタリング条件が関わるシナリオでは、wp_postmeta性能のボトルネックが顕著になる。各属性値が独立した行として保存されるため、属性値に基づくクエリには大量の結合操作やサブクエリが必要となる。特に範囲クエリ、ソート、集計計算を行う場合、データベースはテキスト値を適切な型に変換する必要があり、この追加ステップがクエリのオーバーヘッドを大幅に増加させる。
2.2 複雑なクエリシナリオの比較テスト
典型的な製品カタログのシナリオを考えてみましょう:特定の価格帯に属し、在庫が十分で、かつ特定のカテゴリに分類される製品をすべて検索する必要があります。使用wp_postmetaこのクエリは少なくとも3回のテーブル結合操作を必要とし、各結合は記事IDと特定の属性名に基づいて行われます。フィルタ条件が増えるにつれて、クエリの複雑さは線形に増加します。
対照的に、カスタムデータテーブル方式では、これらすべての属性を同一行の異なる列に格納します。クエリは単一テーブルに対する条件フィルタリングに簡素化でき、データベースは複合インデックスを活用してこの処理を高速化できます。テストデータによると、数万件のレコードを含むデータセットにおいて、カスタムテーブル方式のクエリ速度は通常、wp_postmetaソリューションは5倍から20倍高速であり、具体的な差はクエリの複雑さに依存する。
2.3 書き込み操作の性能に関する考慮事項
データ書き込みの面でも、両方のソリューションの差異は同様に顕著である。wp_postmeta各更新は独立したデータ行操作を伴い、記事に大量のメタデータを更新する必要がある場合、複数のデータベース書き込みリクエストが発生します。WordPressはこれらの操作をバッチ処理しようとしますが、基盤となるのは依然として複数の独立した挿入または更新です。
カスタムデータテーブルの更新は通常単一行内で行われ、データベースのトランザクション処理メカニズムが関連フィールドの更新の原子性を保証します。この単回操作モードはデータベースロック競合を減らし、高並行書き込みシナリオにおいてより優れたパフォーマンス安定性を発揮します。
三、拡張性と長期メンテナンスの総合評価
3.1 データ構造の進化の難易度
プロジェクトの要求が時間とともに変化するのは常態であり、データストレージソリューションはこの進化に適応する必要がある。wp_postmetaこのソリューションはフィールドの追加・削除に対応する点で自然な強みを持つ。新規フィールドの追加にはデータベース構造の変更が不要で、コード内で新しいプロパティ名の使用を開始するだけで済む。この柔軟性は、迅速な反復開発環境において非常に魅力的である。
しかし、この柔軟性は保守負担となる可能性もある。時間の経過とともに、異なるバージョンのプラグインが同じ意味のデータを異なる属性名で保存したり、同じ属性名が異なる文脈で異なる意味を持つようになるかもしれない。明確なアーキテクチャ文書が欠如している場合、このような暗黙的なデータ構造は理解と保守が困難になる。
カスタムデータテーブルは明示的な構造変更を必要とします。新しいフィールドを追加するには実行が必要です。ALTER TABLE文これにはより厳格な変更管理とダウンタイムの可能性が必要となります。しかし、このような明示的な変更は明確なアーキテクチャ文書を生み出し、各フィールドの追加・修正・削除が明確に記録されます。長期的な保守の観点から見ると、この明確さは短期的な利便性よりも価値がある場合が多いのです。
3.2 WordPressエコシステムとの互換性
wp_postmetaWordPressの無視できない強みは、そのコア機能との深い統合性にある。記事の改訂履歴、自動下書き保存、ゴミ箱機能といった多くの組み込み機能は、メタデータシステムと密接に連携している。カスタムデータテーブルを使用する場合、これらの機能の統合を独自に実装するか、あるいは一部のコア機能が欠落することを受け入れる必要がある。
一方、カスタムデータテーブルはより明確な境界分離を提供します。業務データとコンテンツ管理データは異なる物理テーブルに保存され、この分離によりデータモデルが理解しやすくなり、バックアップと復旧戦略も簡素化されます。外部システムとの統合が必要なシナリオでは、明確なデータ境界が結合の複雑さを軽減します。
3.3 移行とデータ変換の複雑性
プロジェクトがwp_postmetaカスタムデータテーブルへの移行において直面する主な課題はデータクリーニング構造変換。メタデータテーブルのデータには、不整合なフォーマット、重複レコード、または無効な値が含まれる可能性があります。移行プロセスでは、これらのデータ品質問題を慎重に処理する必要があります。
逆方向の移行は複雑度が低いものの、一部の情報を失う可能性があります。カスタムテーブルの厳格な型制約は、テキストストレージへの変換時に精度や意味情報が失われる恐れがあります。
四、実践指導:シナリオベースの意思決定フレームワーク
4.1 wp_postmetaの適切な適用シナリオを明確化する
特定のタイプのプロジェクトには、採用がより適している。wp_postmetaソリューション。この種のプロジェクトは通常、以下の特徴を備えています:データ構造がシンプルで安定しており、各エンティティの属性数が限られている;クエリパターンは単一エンティティを中心に構成され、エンティティを跨ぐ複雑なクエリがほとんど不要;プロジェクト規模が小さく、データ量が限定的;WordPressの組み込み機能(リビジョン履歴や自動保存など)を最大限に活用する必要がある。
典型的な適用シーンには、シンプルなコンテンツ型ウェブサイト、ブログプラットフォーム、宣伝展示ページなどが含まれます。これらのシーンでは、コンテンツのメタデータ要件が比較的固定されており、性能要求は高くなく、開発効率が実行効率よりも優先されます。
4.2 カスタムデータテーブルが必要なプロジェクト特性の識別
プロジェクトが以下の特徴を示す場合、カスタムデータテーブルの採用を真剣に検討すべきである:- データ構造が複雑で、明確なビジネスエンティティと関係性を持つ- クエリ要件が多様かつ複雑で、複数条件によるフィルタリング、集計計算、またはソート操作を伴う- データ量が大幅に増加し、数万から数百万レコードに達すると予測される- 外部システムとのデータ交換または統合が必要である- クエリ性能に対する要求が高く、応答時間が業務効果に直接影響する
典型的な適用シーンには、電子商取引プラットフォーム、会員管理システム、オンライン予約システム、学習管理システムなどが含まれる。これらのシステムは通常、明確なビジネスモデルを持ち、データ関係が複雑で、厳格な性能要件が求められる。
4.3 混合戦略の合理的な運用
実際のプロジェクトでは、単一の方式を完全に採用することが最善の選択とは限らない。ハイブリッド戦略により、異なるデータタイプの特性に応じて最適な保存方法を選択できる。
コアコンテンツデータは引き続きWordPressの標準記事とメタデータシステムプラットフォーム機能との完全な互換性を維持します。業務固有の構造化データはカスタムデータテーブルで保存され、パフォーマンス上の優位性と型安全性を実現します。両システムは記事IDを介して関連付けられ、必要に応じてデータ結合クエリを実行します。
このハイブリッドソリューションは、互換性とパフォーマンス、開発効率と実行効率のバランスを取っています。より緻密なアーキテクチャ設計を必要としますが、複雑なプロジェクトにおいて最適な全体的な効果をもたらすことがよくあります。

五、まとめ:バランスの芸術
データストレージソリューションの選択は、本質的に異なる次元のニーズのトレードオフプロセスである。wp_postmetaこのソリューションは開発効率、柔軟性、およびエコシステム統合において優位性を持つ一方、カスタムデータテーブルはクエリ性能、データ整合性、長期的な保守性においてより優れたパフォーマンスを発揮する。
絶対的な正解はなく、特定の文脈における最適な選択があるだけです。この決定は、プロジェクト要件の深い理解、データ成長パターンの合理的な予測、そしてチームの技術能力に対する客観的な評価に基づいて行うべきです。賢明な開発者はプロジェクト初期に時間をかけてアーキテクチャ分析を行います。なぜなら、この基盤レベルでの選択がプロジェクトのライフサイクル全体を通じて持続的な影響を与えるからです。
WordPressがより包括的なアプリケーションプラットフォームへと進化するにつれ、データストレージアーキテクチャの選択はますます重要になっています。組み込みのメタデータシステムを使い続ける場合でも、カスタムデータテーブルを導入する場合でも、目標は常に信頼性が高く、保守可能で、ビジネスニーズを満たすソリューションを構築することです。この二つのアプローチの本質を理解することが、賢明な技術的判断を下す第一歩となります。
| お問い合わせ | |
|---|---|
| チュートリアルが読めない?無料でお答えします!個人サイト、中小企業サイトのための無料ヘルプ! |

カスタマーサービス WeChat
|
| ① 電話:020-2206-9892 | |
| ② QQ咨询:1025174874 | |
| 三 Eメール:[email protected] | |
| ④ 勤務時間: 月~金、9:30~18:30、祝日休み | |
この記事へのリンクhttps://www.361sale.com/ja/82343/この記事は著作権で保護されており、必ず帰属表示を付けて複製してください。













![絵文字[wozuimei]-Photonflux.com|プロのWordPress修理サービス、ワールドワイド、迅速対応](https://www.361sale.com/wp-content/themes/zibll/img/smilies/wozuimei.gif)
![表情[baoquan]-光子波动网 | 専門WordPress修復サービス、全世界対応、迅速対応](https://www.361sale.com/wp-content/themes/zibll/img/smilies/baoquan.gif)







コメントなし