





为什么需要自动化运营日报?

做运营的人都知道,每天早上第一件事就是整理昨天的数据:流量多少、转化多少、哪篇文章涨了、哪个渠道掉了。这件事重复、机械、但又不能不做。
OpenClaw 的定时任务(Cron)功能可以让 AI 每天固定时间自动生成日报,并推送到你的 Telegram 群、Discord 频道或 Slack workspace。你早上打开手机,日报已经在群里等着你了。
这篇教程教你从零配置一个每日自动运营日报。
整体思路
实现自动日报需要三个部分配合:
- 调度器(Schedule):告诉 OpenClaw 什么时候执行,比如每天早上 9 点
- 执行体(Payload):告诉 AI 要做什么,比如”生成昨天的运营数据摘要”
- 推送(Delivery):告诉 OpenClaw 把结果发到哪里,比如 Telegram 群
三者组合起来就是一个完整的 cron job。
第一步:理解 Cron 定时任务机制
OpenClaw 的 Cron 运行在 Gateway 进程内部,不依赖系统的 crontab。它有三种调度方式:
- at:一次性任务,到点执行一次就删除
- every:固定间隔重复,比如每 6 小时一次
- cron:标准 cron 表达式,支持时区设置
做日报用 cron 类型最合适,因为你需要”每天早上 9 点”这种精确的时间控制。
第二步:创建每日 9 点执行的 Cron Job
用 CLI 一行命令就能创建:
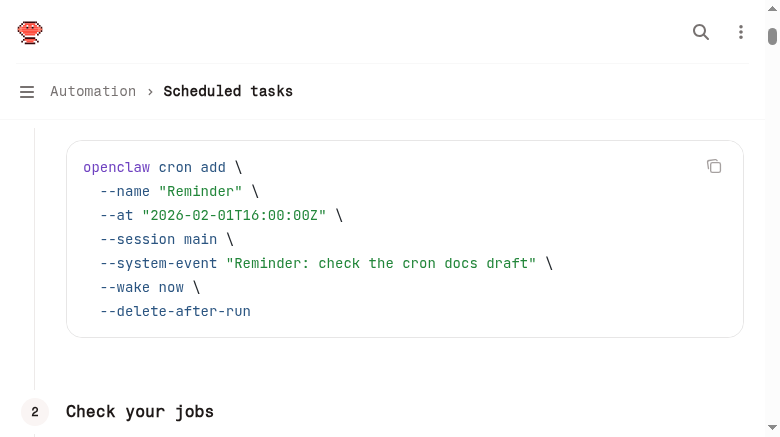
openclaw cron add \
--name "每日运营日报" \
--cron "0 9 * * *" \
--tz "Asia/Shanghai" \
--session isolated \
--agent-turn "请生成昨天的运营数据日报,包括:网站总流量、Top 5 文章、新增收录数、关键词排名变化、异常告警。用简洁的列表格式输出。" \
--delivery announce \
--delivery-channel telegram \
--delivery-to "-100123456789"
这条命令做了什么:
--cron "0 9 * * *":每天 9:00 执行--tz "Asia/Shanghai":按上海时间算(不设的话默认 UTC)--session isolated:在独立会话中执行,不影响你的主对话--agent-turn "...":让 AI 执行的具体指令--delivery announce:执行完把结果推送出去--delivery-channel telegram:推送到 Telegram--delivery-to "-100123456789":目标群组 ID
第三步:配置 Payload——让 AI 知道该做什么
Payload 是 cron job 的核心,决定 AI 执行什么任务。对于日报场景,你需要在 prompt 里写清楚:
- 要汇总哪些数据
- 数据来源是什么(Google Analytics、Search Console、数据库)
- 输出格式是什么
如果你的 AI 已经配置了相关工具(比如能访问 Google Analytics API),它就能自动拉取真实数据。如果没有,它会基于你之前的对话记录和记忆生成摘要。
用 JSON5 格式写配置文件会更清晰:
{
name: "每日运营日报",
schedule: {
kind: "cron",
expr: "0 9 * * *",
tz: "Asia/Shanghai"
},
payload: {
kind: "agentTurn",
message: "请生成昨天的运营数据日报。包括:1) 网站总 UV/PV;2) Top 5 流量文章;3) Google 新收录页面数;4) 关键词排名变化(涨/跌超过 3 位的);5) 异常告警(如果有 5xx 错误或流量暴跌)。用简洁列表格式,不要废话。",
timeoutSeconds: 120
},
delivery: {
mode: "announce",
channel: "telegram",
to: "-100123456789"
},
sessionTarget: "isolated"
}
把这个保存为 daily-report.json5,然后用命令导入:
openclaw cron add --file daily-report.json5第四步:配置 Delivery——把日报推送到群里
OpenClaw 支持三种推送方式:
- announce:推送到聊天渠道(Telegram/Discord/Slack 等)
- ウェブフック:POST 到一个 URL(适合对接内部系统)
- なし:不推送,只记录(适合调试)
推送到不同平台的配置示例:
推送到 Telegram 群
{
delivery: {
mode: "announce",
channel: "telegram",
to: "-100123456789"
}
}
推送到 Discord 频道
{
delivery: {
mode: "announce",
channel: "discord",
to: "1234567890"
}
}
推送到 Slack
{
delivery: {
mode: "announce",
channel: "slack",
to: "C0123456789"
}
}
怎么找群组 ID?
- Telegram:把 Bot 加入群组后,在
openclaw logs --follow里看 chat.id - Discord:开启开发者模式,右键频道复制 ID
- Slack:频道详情里的 Channel ID
第五步:查看运行历史
创建 cron job 后,你可以随时查看它的执行记录:
# 列出所有 cron job
openclaw cron list
# 查看某个 job 的详情
openclaw cron get <job-id>
# 查看执行历史
openclaw cron runs --id <job-id>
# 手动触发一次(用于测试)
openclaw cron run <job-id>
建议创建完之后先用 openclaw cron run 手动触发一次,确认 AI 能正常生成日报、推送能正常到达,再等第二天自动执行。
第六步:常见问题排查
如果日报没有按时推送,按以下顺序排查:
- うごく
openclaw cron list确认 job 状态是 enabled - うごく
openclaw cron runs --id <job-id>看最近一次执行是 succeeded 还是 failed - 如果是 failed,检查 payload 里的 prompt 是否有问题
- 如果是 timed_out,增加 timeoutSeconds 的值
- 如果推送没到达,检查 delivery 的 channel 和 to 是否正确
一般的な問題
Q1:cron job 创建后多久开始执行?
创建后立即生效。如果你在下午 3 点创建了一个”每天早上 9 点”的任务,它会在第二天早上 9 点第一次执行。想立即测试,用 openclaw cron run <job-id>.
Q2:Gateway 重启后 cron job 会丢失吗?
不会。所有 job 定义持久化在 ~/.openclaw/cron/jobs.json,重启后自动恢复。
Q3:能不能让日报包含真实的 Google Analytics 数据?
可以,但需要给 AI 配置相应的工具(MCP server 或 API 访问权限)。如果没有配置数据源工具,AI 只能基于它已有的记忆和上下文生成摘要。
Q4:一个 cron job 能同时推送到多个群吗?
目前一个 job 只能配置一个 delivery 目标。如果需要推送到多个群,创建多个 job,payload 相同但 delivery.to 不同即可。
Q5:时区设置错了怎么改?
支出 openclaw cron update <job-id> --tz "Asia/Shanghai" 修改。或者直接编辑 ~/.openclaw/cron/jobs.json,Gateway 会自动检测文件变化并重新加载。
Q6:执行超时怎么办?
默认超时时间可能不够复杂任务使用。在 payload 里加 timeoutSeconds: 300(5 分钟)给 AI 更多时间。如果任务确实很重,考虑拆分成多个小任务。
相关教程推荐
- OpenClaw 怎么做数据分析日报?每天 5 分钟掌握网站运营状态
- OpenClaw 怎么做内容排期?把关键词研究变成可执行的发布计划
- OpenClaw 怎么复盘 SEO 数据?从收录检查到内容优化的完整流程
概要
用 OpenClaw 做自动化日报的核心就是三步:设好时间(schedule)、写好指令(payload)、配好推送(delivery)。一次配置,每天自动执行,再也不用早上手动整理数据了。
更多定时任务的高级用法,参考官方文档:OpenClaw Scheduled Tasks 文档.
官方文档:OpenClaw 定时任务文档
| お問い合わせ | |
|---|---|
| チュートリアルが読めない?無料でお答えします!個人サイト、中小企業サイトのための無料ヘルプ! |

カスタマーサービス WeChat
|
| ① 電話:020-2206-9892 | |
| ② QQ咨询:1025174874 | |
| 三 Eメール:[email protected] | |
| ④ 勤務時間: 月~金、9:30~18:30、祝日休み | |
この記事へのリンクhttps://www.361sale.com/ja/87565/この記事は著作権で保護されており、必ず帰属表示を付けて複製してください。















0
今はまだ間違いなくSEOを行っているが、ただ遊び方が変わっただけだ。 以前はコンテンツの山に依存し、キーワードの山は、トラフィックを持つことができ、今ではコンテンツの質+ブランドの信頼+ユーザーエクスペリエンスにもっと注意を払う。 SEOだけに頼ることに加えて、実際にはますます困難であり、多くの良い基本的にSEO +ソーシャルメディア+コンテンツマーケティング+一緒に行うには、プライベートドメインの変換。 SEOは依然として長期的な顧客獲得チャネルであるが、もはや唯一のチャネルとして捉えることはできない。ヒヒは仕事中
3月11日 10:540
ノーマルは、Googleに代わってページを参照してくださいにのみ含まれ、すぐにランキングにそのことを意味するものではありませんが、"含まれているが、ランク付けされていない "通常のため: キーワードの競争は、ページの重量が低い、コンテンツが十分に強力ではない、ページが比較的新しいです。 ロングテールキーワード、コンテンツの品質と内部チェーンを最適化し続け、通常は少し時間がかかり、ランキングは徐々に出てくるだろう!アメリア・フォスター 3月6日 16:200
スクリーンショットはありますか?魚でない息子も魚の喜びを知っている。 3月6日 09:230
最初に最適化プラグインを積み上げるのではなく、最初にボトルネックを特定する: クエリモニタを使って、遅いSQL、遅いフックを確認する。 すべてのプラグインを一時停止して比較し、それから1つずつオンにする。 オートロードが大きすぎないかチェックする(オプションテーブル)。 大きなテーブルクエリでデータベースのインデックスをチェックする。 サーバーのTTFBが高い場合は、まずホスト/データベースのパフォーマンスに取り組んでください。ヒヒは仕事中
3月3日 16:470
ウィンドジャマーさん、複雑なローカル環境をいじくる必要はありません。普通の人はこの手順に従って更新すれば、基本的にサイトがクラッシュすることはありません👇。 まず、サイト全体のバックアップ、ファイル+データベースの準備、これが肝心です。 サイトのアップデートをする場合、ワンクリックで全部行わず、一括で行い、まず重要でないプラグインを変更し、次にコアなプラグインを変更する。 更新後すぐにキャッシュをクリアし、フォアグラウンドに移動してトップページ、記事ページ、ボタン、フォーム、これらの重要な位置をチェックする。 バージョンのロールバックをサポートするプラグインをインストールしておくと、クラッシュした場合、一瞬で古いバージョンに戻すことができる。 まとめると:まずバックアップ、一括変更、変更後チェック、戻る方法を残す、非常に安定している ✅😎 これが役立つことを願っています!バグバング 3月2日 09:550
通常、決済がうまくいかなかったのではなく、コールバック(ウェブフック)が注文状況を書き戻さなかったのです。 トラブルシューティングの手順 WooCommerce → Status → Logs: ペイメントゲートウェイにウェブフックエラー/シグネチャーエラー/タイムアウトがあるか確認してください。 サイトがWAF(Cloudflare、Pagoda Firewall、セキュリティプラグイン)によってブロックされていないか確認する。 Cache checkout pages/interface paths "が有効になっているか確認する(チェックアウトページとコールバックインターフェースはキャッシュされるべきではない) サーバーのエラーログを見て、コールバックの実行を中断させるような500/致命的なエラーがないか確認する。 解決方法 wp-json、wc-api、ペイメントゲートウェイのコールバックURLを解放する。 チェックアウトページのキャッシュとJSマージ圧縮テストを一度無効にする。 Cloudflareを使用している場合: コールバックURLのno-challenge、no-blockルールを設定する。ウラ・ナラ・ジェンファン(18嬛嬛) 1月31日 09:360
1) 「正常な待機」なのか「異常な停滞」なのかを判断する。 まず3つのシグナルを見ることができる:ページ公開時間が7-14日以内か、このステータスのページは少数か、XMLサイトマップにページが登場しているか。 この3つが満たされていれば、通常のクロールと評価の段階である可能性が高く、すぐに行う必要はない。 2)どのような場合に「待つ」ことが無駄になるのか? 内部リンクがほとんどないページ(孤立したページ)、サイト内の既存ページと内容が酷似している、カノニカルポイントが他のURLになっている、同じトピックで似たような記事が短期間に公開されすぎている、などの場合は、時間が経過しても自動的には解決されません。 この場合、Googleはクロールはしているが「インデックスに登録する価値はない」と判断している。 3)手動で介入する最も効果的な方法(手間をかけない) 内部リンクの追加、関連する古い記事やコラムからページへのリンク、最初の画面の情報密度を高める。 最初の2-3段落はユーザーの質問に直接答える、詰め込みすぎを避ける、重複ページと判定されないようにcanonicalを自己参照として確認する、そしてGSCに再インデックスを依頼しに行く。 4) 逆効果になる「介入行動」とは? 頻繁に削除や再投稿を繰り返す、「インデックスリクエスト」を何度も連続でクリックする、インデックスされるためにキーワードを無理やり重ねる、URLやタイトルを恣意的に変更する、など。 これらの操作は、Googleにページの安定性を再評価させるが、インクルードが遅くなる。 5) 現実的な判断基準 記事:クロールされている、noindex/robotsの問題がない、少なくとも1-2個の関連する内部リンクがある、コンテンツが明らかに独立した問題を解決している、プラグインの問題ではなく時間の問題である。ポスト・ポーター 1月30日 10:000
新しい駅は完全に外部リンクを行うことはできませんが、最初のコンテンツと駅の構造は、より安定した良い仕事をする。コンテンツにのみ依存して、一般的にロングテールの単語のランキングの一部が含まれて得ることができますが、高い競争の量が遅くなります。それは、サイトが安定してインクルード、30〜50品質のコンテンツを待つことをお勧めします、キーワードはトップ20/30を入力するようになったし、外部リンクの少量は、優先順位のブランド語/裸チェーン/引用型は、番号を追いかけて出てこない。👍