



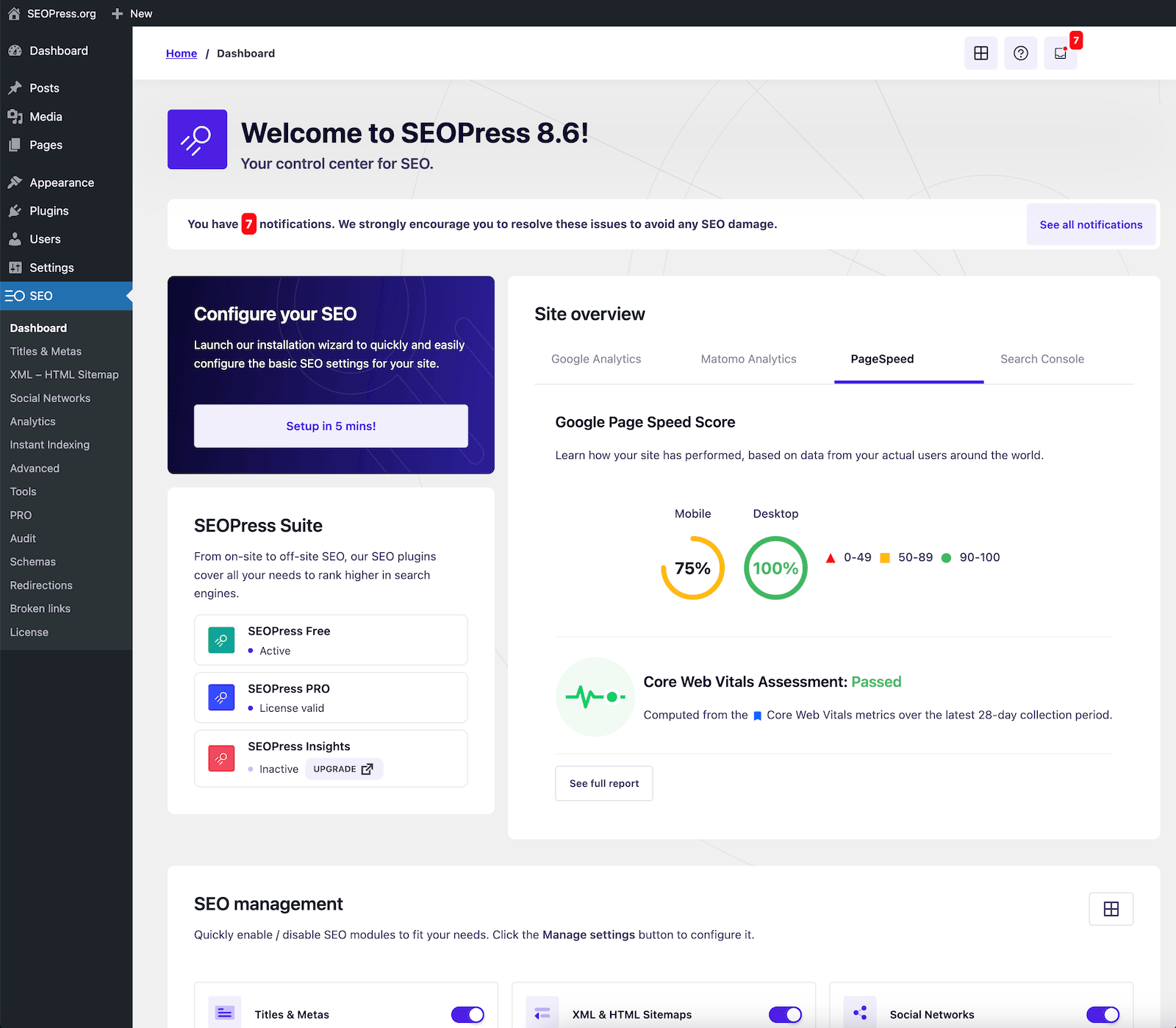
A la hora de abordar el SEO en WordPress, los errores más comunes no residen en «qué escribir», sino en «qué debe permanecer oculto»: presupuesto de rastreo desperdiciado, páginas duplicadas que saturan la indexación y páginas funcionales que aparecen por error en los resultados de búsqueda. En la práctica, hay que recordar dos aspectos esenciales: la sección «Ajustes de lectura» del backend incluye una opción para activar o desactivar la visibilidad de todo el sitio, mientras que las reglas más detalladas requieren una gestión por tipo de página; como alternativa, primero se puede organizar por...Guía completa para configurar Robots.txtEl enfoque consiste en tratar la «rastreabilidad» y la «indexabilidad» como capas separadas.
![Imagen [1] - robots.txt Guía definitiva: Prevención de indexación en WordPress y estrategia noindex](https://www.361sale.com/wp-content/uploads/2026/01/20260104174515992-image.jpeg)
1. En primer lugar, comprenda las funciones distintas de robots.txt y noindex.
1.1 ¿Desea controlar el «acceso» o la «aparición en los resultados»?
El archivo robots.txt funciona más bien como un sistema de control de acceso: indica a los rastreadores qué áreas deben evitar, lo que ayuda a reducir el rastreo innecesario y a evitar el acceso frecuente a los directorios del sistema. Sin embargo, esto no equivale a «desaparecer de los resultados de búsqueda», ya que los enlaces pueden seguir apareciendo a través de referencias externas o de la navegación interna.
noindex funciona más bien como una etiqueta de desindexación: la página sigue siendo accesible, pero se indica explícitamente a los motores de búsqueda que no la incluyan en su índice. Para una «exclusión de la indexación» genuina, priorice noindex; para «conservar los recursos de rastreo», utilice robots.txt de forma conjunta.
1.2 Conceptos erróneos comunes sobre su combinación
Muchos sitios primero bloquean el rastreo de determinadas páginas mediante el archivo robots.txt y, a continuación, añaden etiquetas noindex a dichas páginas. Este enfoque suele ser contraproducente: si el rastreador no puede acceder a la página, no verá la instrucción noindex, lo que puede dejar la página en un estado prolongado de «descubierta pero no procesada». Un enfoque más fiable consiste en mantener las páginas que requieren noindex accesibles para los rastreadores, colocando el punto de control en la etiqueta meta o en el encabezado de respuesta.
2. ¿Qué páginas deben marcarse como noindex? Da prioridad al contenido escaso y a las páginas funcionales.
2.1 Página de proceso funcional: útil para los usuarios, pero sin sentido para la búsqueda.
Las páginas como los carritos de la compra, el proceso de pago, los centros de cuentas, los detalles de los pedidos, los resultados de búsqueda interna y las pantallas de inicio de sesión/registro presentan contenido muy personalizado o carecen de información reutilizable. Su aparición en los resultados de búsqueda puede reducir la calidad general y provocar posibles problemas de privacidad y conversión. Si gestionas las reglas con Yoast, puedes hacer referencias cruzadas.Tutorial Yoast SEOEstablece todas esas páginas funcionales como noindex.
2.2 Páginas de agregación de archivos: indexar el contenido cuando sea posible; aplicar noindex cuando no sea posible.
Los archivos de autor, los archivos de fecha, los archivos de etiquetas, las páginas de categorías vacías y las páginas de paginación profunda suelen adolecer de los problemas habituales de «demasiados listados, muy poca información y diferenciación mínima». Si estás dispuesto a complementar estas páginas de archivo con descripciones, contenido seleccionado y navegación estructurada, pueden convertirse en puntos de entrada de cola larga; por el contrario, implementa de forma decisiva noindex para evitar la duplicación y la dilución. Para obtener una solución rápida a las páginas de categorías y etiquetas vacías, consultaOcultar directorios de categorías redundantesEl enfoque consiste en cerrar primero las «páginas agregadas que carecen de contenido sustantivo».
2.3 Páginas adjuntas y páginas generadas automáticamente: priorizar el procesamiento en todo el sitio
Muchos temas generan páginas de adjuntos para cada imagen, que suelen contener solo una imagen y un texto mínimo, lo que las hace prácticamente carentes de valor para las búsquedas. Una estrategia superior consiste en redirigir estas páginas de adjuntos al archivo multimedia o al contenido principal correspondiente, al tiempo que se configuran los plugins de SEO para que, por defecto, no indexen los tipos de adjuntos. Este enfoque frena la proliferación de «contenido pobre».
3. Qué rutas deben incluirse en robots.txt: Evita que los rastreadores den vueltas sin cesar en segundo plano.
3.1 Recursos del backend y del sistema: minimizar el rastreo inútil
El área de administración backend, las interfaces del editor, los directorios de recursos de plugins, los archivos temporales y los directorios de caché no deben aparecer en los resultados de búsqueda ni ser rastreados con frecuencia. El propósito de incluirlos en el archivo robots.txt es reservar tiempo de rastreo para las páginas de artículos, páginas de productos y páginas de categorías principales.
3.2 La verdadera privacidad no debe depender únicamente del archivo robots.txt.
robots.txt no es ni un sistema de cifrado ni un control de permisos. La protección de los datos de las cuentas, la información de los pedidos y el contenido de los miembros debe basarse en permisos de inicio de sesión, interceptación del lado del servidor y estrategias de almacenamiento en caché adecuadas, en lugar de depositar todas las esperanzas en una sola línea de reglas de exclusión.
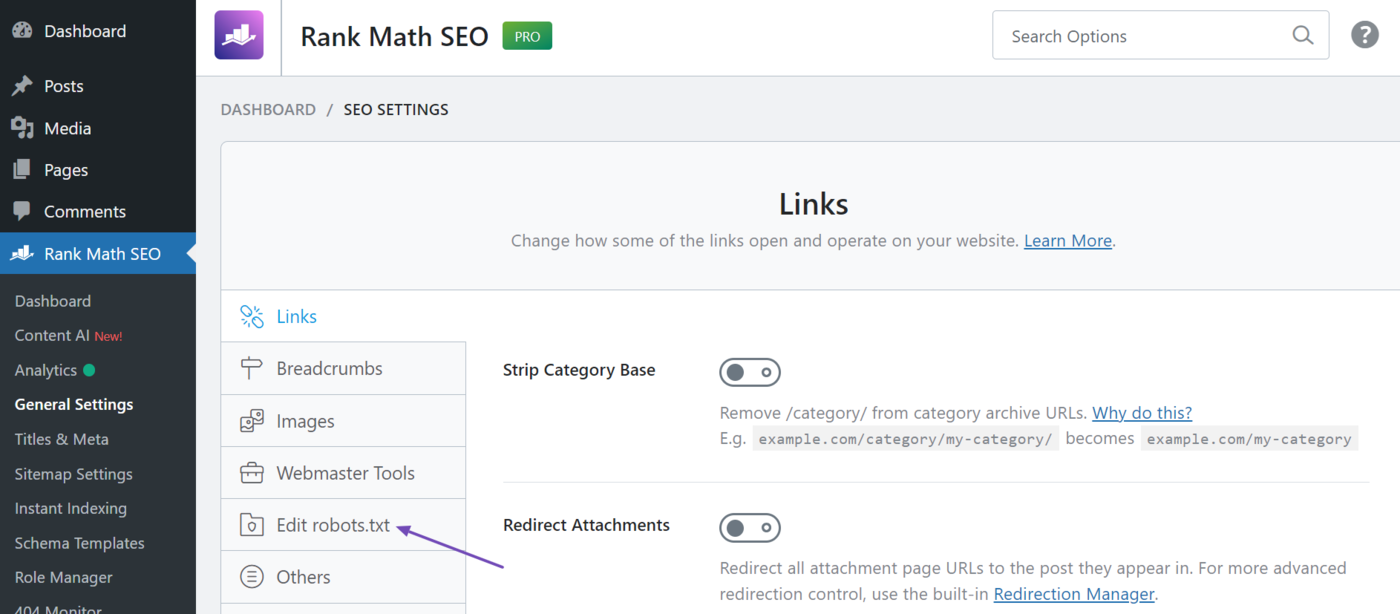
4. Implementar mediante complementos: establecer reglas como «valores predeterminados mantenibles».
4.1 Mantenimiento unificado de robots.txt a través del editor visual
Si desea gestionar las reglas de los robots a través de una interfaz, es recomendable centralizarlas en un único punto de entrada para evitar la fragmentación o los descuidos durante el trabajo colaborativo. Al editar, concéntrese únicamente en dos tareas: bloquear áreas del sistema que claramente no tienen valor y declarar las ubicaciones del mapa del sitio. Evite añadir indiscriminadamente «páginas que requieren no indexar» a la lista de prohibiciones.
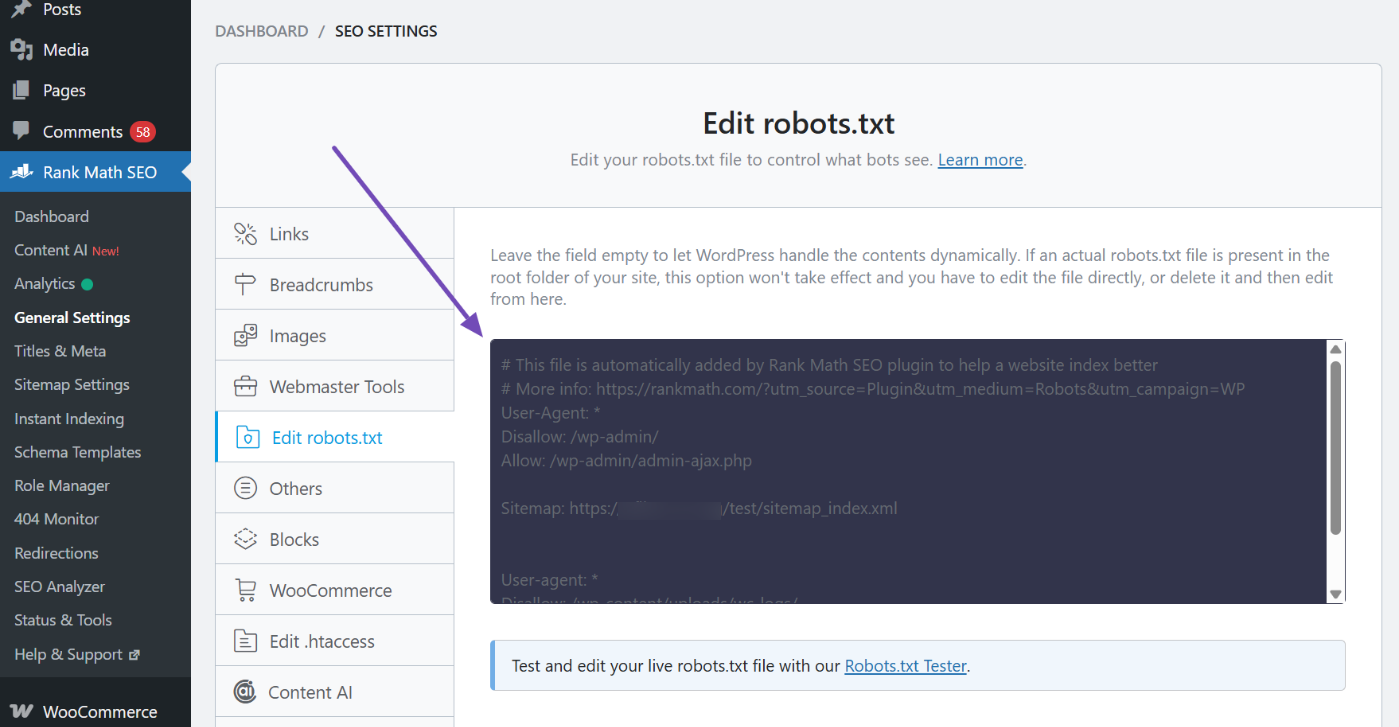
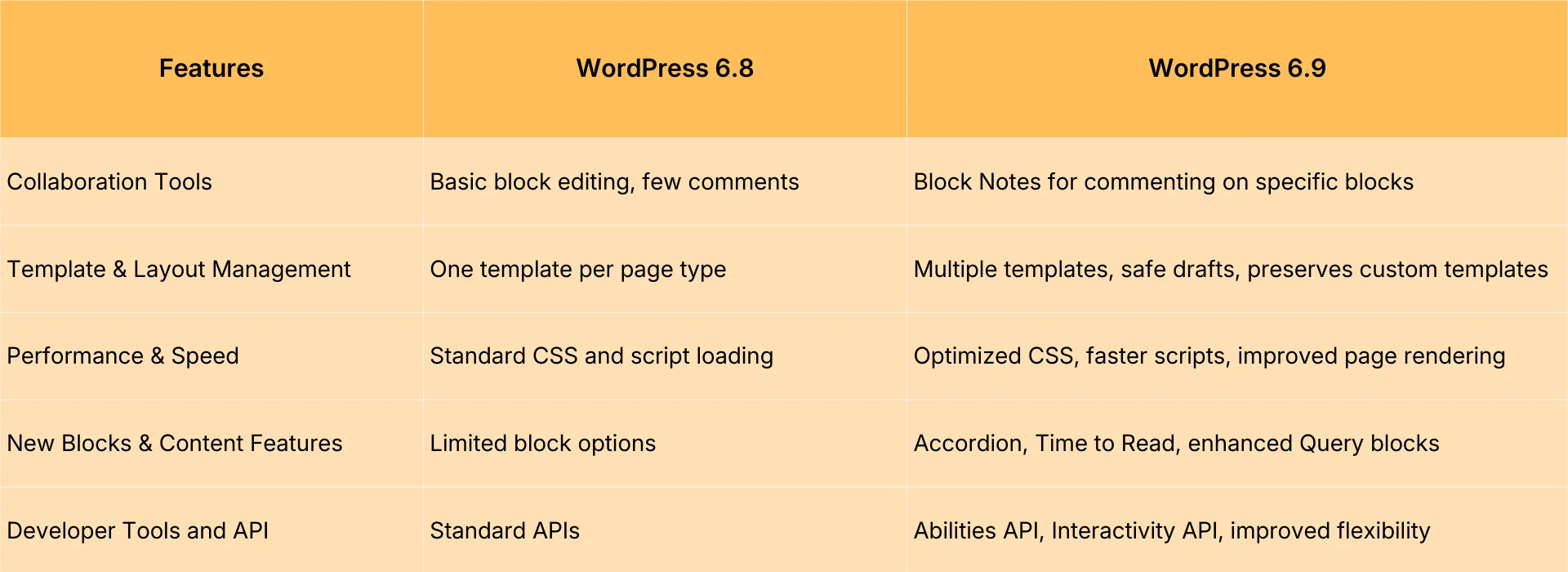
4.2 Una vez modificadas las reglas, se deben realizar pruebas de regresión.
Después de cada ajuste, prueba al menos cuatro tipos de páginas: páginas de contenido principal, páginas de categorías principales, páginas de archivo típicas y páginas de características típicas. Confirma qué páginas se pueden rastrear y cuáles están bloqueadas. Especialmente después de cambiar temas, cambiar plugins o habilitar el almacenamiento en caché o CDN, las pruebas de regresión evitan que «las reglas se sobrescriban sin que nadie se dé cuenta».
![Imagen [4] - robots.txt Guía práctica definitiva: prevención de indexación en WordPress y estrategia Noindex](https://www.361sale.com/wp-content/uploads/2026/01/20260104175117593-Testing-robots.txt-file-1.png)
4.3 Uso de la etiqueta meta robots para controlar «si se indexa»
Coloca puntos de control noindex dentro del metaetiqueta Robots: establece primero una configuración global predeterminada y, a continuación, concede exenciones individuales para un pequeño número de páginas excepcionales. Este enfoque garantiza que las nuevas páginas se publiquen sin omisiones, al tiempo que transforma «qué páginas se pueden indexar» en un estándar ejecutable por el equipo.

5. Sincronización de mapas del sitio y comprobaciones de índices: minimizar los desvíos para los motores de búsqueda.
5.1 Las páginas marcadas con noindex ya no deberían aparecer en el mapa del sitio.
Un mapa del sitio sirve como una «lista de rastreo recomendada». Cuando se marca una categoría de páginas como no indexable, es recomendable eliminarlas del mapa del sitio al mismo tiempo para evitar que los motores de búsqueda descubran repetidamente el mismo lote de páginas que no deben indexarse. Si necesita una lista de verificación, puede consultarla cómodamente.Guía para la creación y optimización de mapas de sitioUnificar lo que se debe informar con lo que se debe ocultar.
5.2 Excepciones de una sola página: páginas Greenlight que realmente satisfacen la intención de búsqueda.
Ciertas páginas que parecen ser archivos pueden convertirse en funciones especiales; algunas páginas funcionales sirven como puntos de entrada dentro de contextos empresariales específicos. A nivel de página individual, se debe permitir anular las políticas predeterminadas: cuando esté seguro de que una página puede responder a las consultas de los usuarios y tiene un valor independiente, cambie su estado de no indexable a indexable y complete su título, contenido y enlaces internos.

6. Un conjunto de criterios listos para su adopción inmediata.
6.1 Método de tres preguntas: determinar si una página debe indexarse
Primera pregunta: ¿Puede abordar de forma independiente una intención de búsqueda sin depender del inicio de sesión o del contenido personalizado? Segunda pregunta: ¿Es lo suficientemente distinta de otras páginas del sitio como para evitar una duplicación significativa? Tercera pregunta: ¿Merece la pena mantenerla a largo plazo y es capaz de mejorar continuamente? Solo si las tres preguntas pueden responderse con un «sí» deberíamos considerar abrirla para su indexación.
6.2 Cuatro categorías de prioridad: concentre sus esfuerzos donde más importan
Priorizar la indexación: páginas de artículos, páginas de productos, páginas de categorías principales y páginas agregadas verdaderamente especializadas. Priorizar noindex: resultados de búsqueda interna, páginas relacionadas con cuentas y pedidos, archivos vacíos y paginación profunda, archivos adjuntos y páginas generadas automáticamente. Priorizar robots.txt: directorios de backend y del sistema, rutas a recursos sin valor añadido. Por último, añadir una capa adicional de arquitectura de la información: a través deTaxonomía de WordPressOrganiza tu contenido de forma más clara y los motores de búsqueda tenderán naturalmente a dar más importancia a las páginas que deseas promocionar. Si las anomalías de indexación parecen estar «en revisión», también es recomendable seguir primero los procedimientos recomendados.Guía completa sobre métodos de recuperaciónElimine los errores de configuración. ::contentReference[oaicite:0]{index=0}
| Contacte con nosotros | |
|---|---|
| ¿No puede leer el tutorial? Póngase en contacto con nosotros para obtener una respuesta gratuita. Ayuda gratuita para sitios personales y de pequeñas empresas |

Servicio de atención al cliente WeChat
|
| ① Tel: 020-2206-9892 | |
| ② QQ咨询:1025174874 | |
| (iii) Correo electrónico: info@361sale.com | |
| ④ Horario de trabajo: de lunes a viernes, de 9:30 a 18:30, días festivos libres | |
Enlace a este artículo:https://www.361sale.com/es/85059El artículo está protegido por derechos de autor y debe ser reproducido con atribución.















![Emoji[wozuimei]-Photonflux.com | Servicio profesional de reparación de WordPress, en todo el mundo, respuesta rápida](https://www.361sale.com/wp-content/themes/zibll/img/smilies/wozuimei.gif)
![Emoticono [baoquan] - Photon Wave Network | Servicios profesionales de reparación de WordPress, cobertura mundial, respuesta rápida](https://www.361sale.com/wp-content/themes/zibll/img/smilies/baoquan.gif)







Sin comentarios