



Lorsque l'on aborde le référencement WordPress, les pièges les plus courants ne résident pas dans « ce qu'il faut écrire », mais dans « ce qui doit rester caché » : budget d'exploration gaspillé, pages dupliquées monopolisant l'indexation et pages de fonctionnalités apparaissant par erreur dans les résultats de recherche. Dans la pratique, retenez deux éléments essentiels : les « Paramètres de lecture » dans le backend permettent d'activer ou de désactiver la visibilité à l'échelle du site, tandis que les règles plus granulaires doivent être gérées par type de page ; vous pouvez également commencer par organiser par...Guide complet pour configurer le fichier robots.txtCette approche consiste à traiter la « crawlabilité » et l'« indexabilité » comme deux couches distinctes.
![Image [1] - robots.txt Guide pratique ultime : prévention de l'indexation WordPress et stratégie noindex](https://www.361sale.com/wp-content/uploads/2026/01/20260104174515992-image.jpeg)
1. Tout d'abord, comprenez les rôles distincts de robots.txt et noindex.
1.1 Cherchez-vous à contrôler « l'accès » ou « l'apparition dans les résultats » ?
Le fichier robots.txt fonctionne davantage comme un système de contrôle d'accès : il indique aux robots d'indexation les zones à éviter, ce qui contribue à réduire l'indexation inutile et à empêcher les accès fréquents aux répertoires du système. Cependant, cela ne signifie pas pour autant que les liens « disparaissent des résultats de recherche », car ils peuvent toujours être découverts grâce à des références externes ou à la navigation interne.
noindex fonctionne davantage comme une balise de désindexation : la page reste accessible, mais les moteurs de recherche reçoivent l'instruction explicite de ne pas l'inclure dans leur index. Pour une véritable « exclusion de l'indexation », privilégiez noindex ; pour « conserver les ressources d'exploration », utilisez robots.txt en complément.
1.2 Idées reçues courantes concernant leur combinaison
De nombreux sites bloquent d'abord l'exploration de certaines pages via le fichier robots.txt, puis ajoutent des balises noindex à ces pages. Cette approche se retourne souvent contre eux : si le robot d'exploration ne peut pas accéder à la page, il ne verra pas l'instruction noindex, ce qui peut laisser la page dans un état prolongé de « découverte mais non traitée ». Une approche plus fiable consiste à garder les pages nécessitant noindex accessibles aux robots d'exploration, en plaçant le point de contrôle dans la balise meta ou l'en-tête de réponse à la place.
2. Quelles pages doivent être marquées comme noindex : donnez la priorité aux pages au contenu pauvre et aux pages fonctionnelles.
2.1 Page de processus fonctionnel : utile pour les utilisateurs, mais sans importance pour les moteurs de recherche.
Les pages telles que les paniers d'achat, les pages de paiement, les centres de compte, les détails de commande, les résultats de recherche interne et les écrans de connexion/inscription contiennent des informations hautement personnalisées ou ne contiennent pas d'informations réutilisables. Leur apparition dans les résultats de recherche peut réduire la qualité globale et potentiellement causer des perturbations en matière de confidentialité et de conversion. Si vous gérez des règles à l'aide de Yoast, vous pouvez effectuer des recoupements.Tutoriel Yoast SEODéfinissez toutes ces pages fonctionnelles sur noindex.
2.2 Pages d'agrégation d'archives : indexez le contenu lorsque cela est possible ; appliquez la balise noindex lorsque cela n'est pas possible.
Les archives d'auteur, les archives par date, les archives par balise, les pages de catégories vides et les pages de pagination profonde souffrent souvent des problèmes courants suivants : « trop de listes, trop peu d'informations et différenciation minimale ». Si vous êtes prêt à compléter ces pages d'archives avec des descriptions, du contenu sélectionné et une navigation structurée, elles peuvent devenir de précieux points d'entrée à longue traîne ; à l'inverse, si ce n'est pas le cas, mettez en œuvre de manière décisive la balise noindex pour éviter la duplication et la dilution. Pour une solution rapide aux pages de catégories et de balises vides, reportez-vous àMasquer les répertoires de catégories inutilesL'approche consiste à commencer par fermer les « pages agrégées dépourvues de contenu substantiel ».
2.3 Pages jointes et pages générées automatiquement : priorité au traitement à l'échelle du site
De nombreux thèmes génèrent des pages de pièces jointes pour chaque image, contenant généralement une seule image et un minimum de texte, ce qui les rend pratiquement sans valeur pour la recherche. Une stratégie plus efficace consiste à rediriger ces pages de pièces jointes vers le fichier multimédia ou le contenu principal correspondant, tout en configurant les plugins SEO pour qu'ils utilisent par défaut l'option « noindex » pour les types de pièces jointes. Cette approche limite la prolifération des « contenus pauvres ».
3. Quels chemins d'accès doivent être inclus dans le fichier robots.txt : empêcher les robots d'exploration de tourner en rond en arrière-plan.
3.1 Ressources backend et système : minimiser le crawling inutile
La zone d'administration backend, les interfaces d'édition, les répertoires de ressources des plugins, les fichiers temporaires et les répertoires de cache n'ont pas besoin d'apparaître dans les résultats de recherche ni d'être explorés fréquemment. Le fait de les répertorier dans le fichier robots.txt a pour but de réserver le temps d'exploration aux pages d'articles, aux pages de produits et aux pages de catégories principales.
3.2 La véritable confidentialité ne devrait pas reposer uniquement sur le fichier robots.txt.
Le fichier robots.txt n'est ni un système de cryptage ni un contrôle d'autorisation. La protection des informations relatives aux comptes, aux commandes et au contenu des membres doit être assurée par des autorisations de connexion, une interception côté serveur et des stratégies de mise en cache appropriées, plutôt que par une simple ligne de règles d'exclusion.
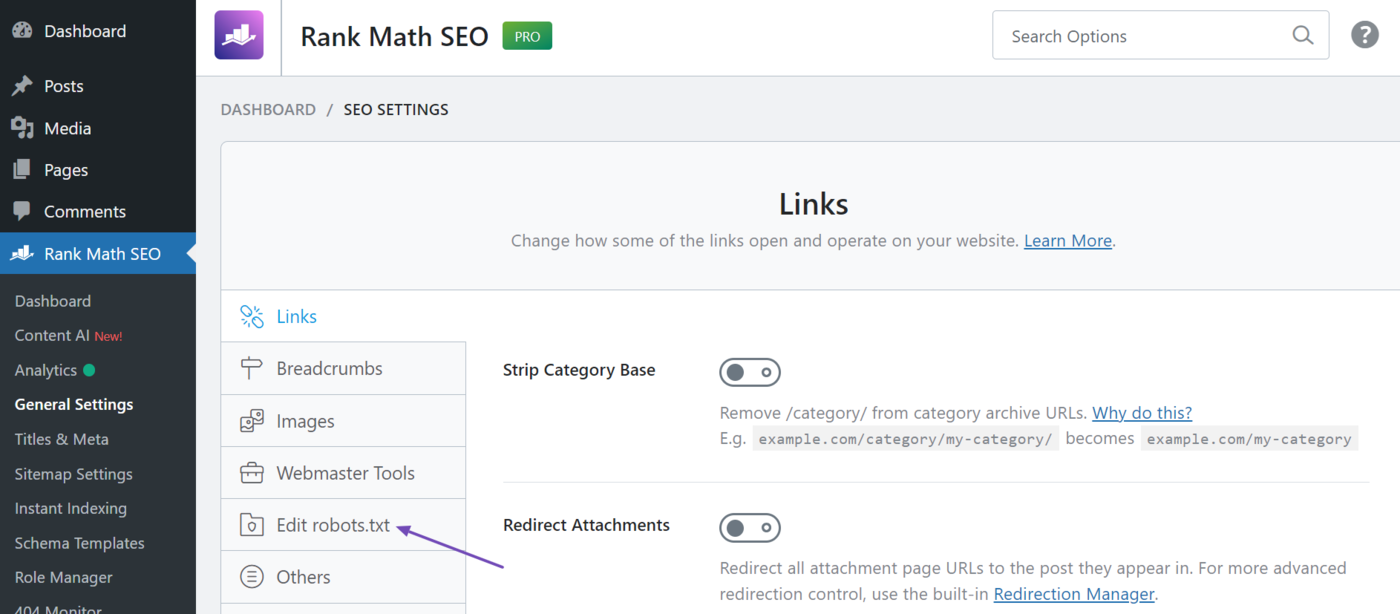
4. Mise en œuvre via des plugins : établir des règles comme « paramètres par défaut faciles à maintenir ».
4.1 Maintenance unifiée du fichier robots.txt via un éditeur visuel
Si vous souhaitez gérer les règles relatives aux robots via une interface, il est conseillé de les centraliser sous un point d'entrée unique afin d'éviter toute fragmentation ou omission lors de l'édition collaborative. Lors de l'édition, concentrez-vous uniquement sur deux tâches : bloquer les zones du système qui n'ont clairement aucune valeur et déclarer les emplacements du plan du site. Évitez d'ajouter sans discernement des « pages nécessitant noindex » à la liste des interdictions.
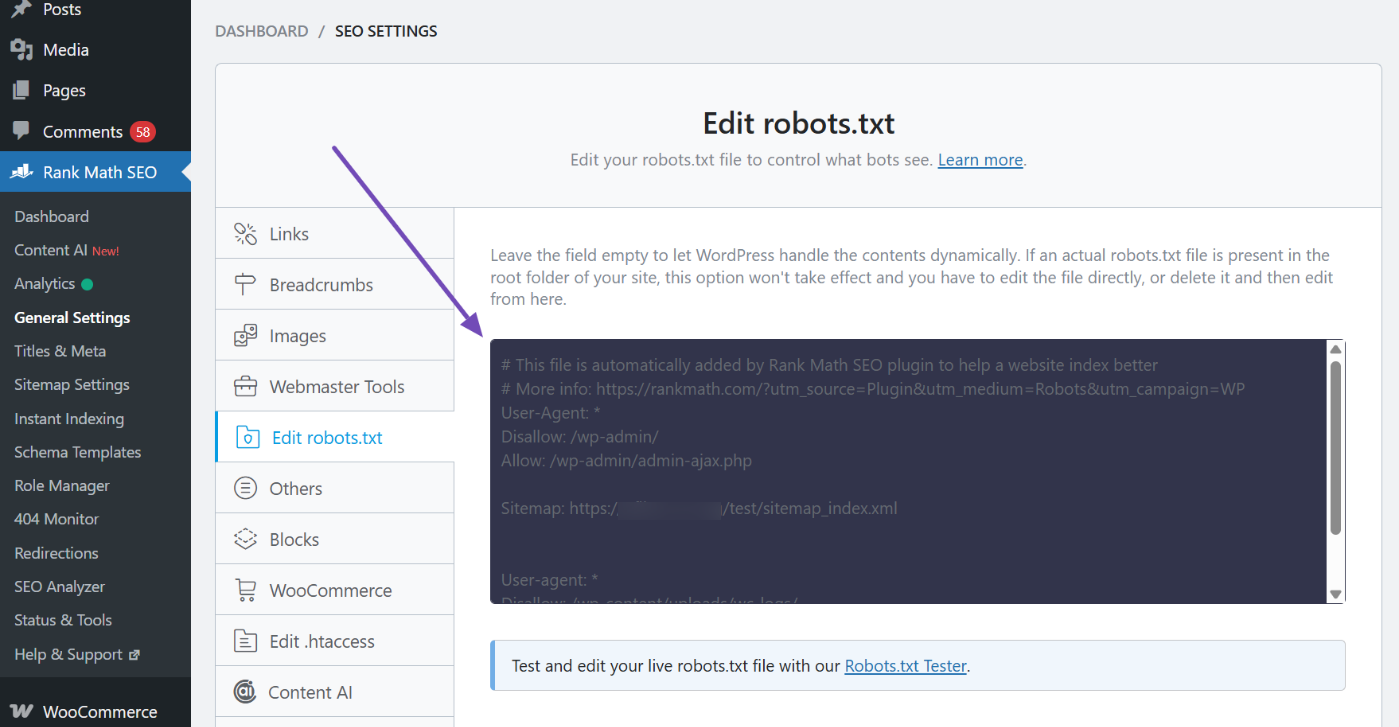
4.2 Une fois les règles modifiées, des tests de régression doivent être effectués.
Après chaque ajustement, testez au moins quatre types de pages : les pages de contenu principal, les pages de catégories principales, les pages d'archives types et les pages de fonctionnalités types. Vérifiez quelles pages peuvent être explorées et lesquelles sont interdites. En particulier après avoir changé de thème, de plugin ou activé la mise en cache ou le CDN, les tests de régression permettent d'éviter que « les règles soient écrasées sans que personne ne s'en aperçoive ».
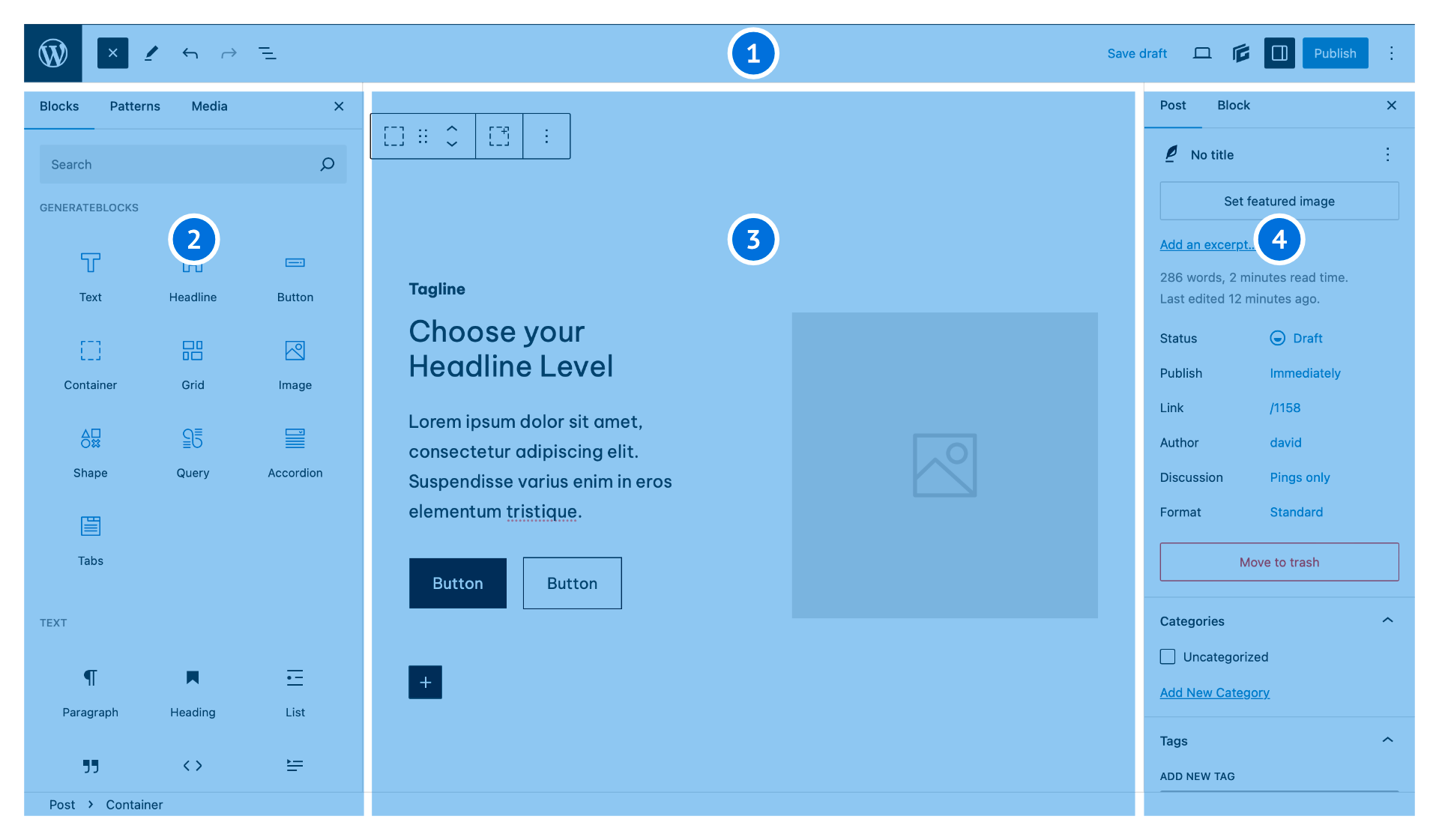
![Image [4] - robots.txt Guide ultime : stratégies WordPress pour empêcher l'indexation et utiliser la balise noindex](https://www.361sale.com/wp-content/uploads/2026/01/20260104175117593-Testing-robots.txt-file-1.png)
4.3 Utilisation de la balise meta robots pour contrôler « l'indexation »
Placez les points de contrôle noindex dans la balise Robots Meta : établissez d'abord un paramètre global par défaut, puis accordez des exemptions individuelles pour un petit nombre de pages exceptionnelles. Cette approche garantit que les nouvelles pages sont mises en ligne sans omission, tout en transformant « quelles pages peuvent être indexées » en une norme exécutable par l'équipe.

5. Synchronisation des plans de site et vérification des index : minimiser les détours pour les moteurs de recherche
5.1 Les pages marquées avec noindex ne devraient plus apparaître dans le plan du site.
Un plan du site sert de liste de crawl recommandée. Lorsque vous marquez une catégorie de pages comme noindex, il est conseillé de les supprimer simultanément du plan du site afin d'éviter que les moteurs de recherche ne découvrent à plusieurs reprises le même ensemble de pages qui ne doivent pas être indexées. Si vous avez besoin d'une liste de contrôle, vous pouvez facilement vous y référer.Guide de création et d'optimisation d'un plan du siteUnifier ce qui doit être divulgué et ce qui doit être dissimulé.
5.2 Exceptions à une seule page : pages Greenlight qui répondent véritablement à l'intention de recherche
Certaines pages qui semblent être des archives peuvent être développées pour devenir des fonctionnalités spéciales ; certaines pages fonctionnelles servent de points d'entrée dans des contextes commerciaux spécifiques. Au niveau des pages individuelles, il convient d'autoriser le remplacement des politiques par défaut : lorsque vous êtes certain qu'une page peut répondre aux requêtes des utilisateurs et possède une valeur indépendante, remplacez son statut « noindex » par « indexable » et assurez-vous qu'elle est complétée par un titre, un contenu et des liens internes.

6. Un ensemble de critères prêts à être adoptés immédiatement
6.1 Méthode en trois questions : déterminer si une page doit être indexée
Première question : peut-elle répondre de manière indépendante à une intention de recherche sans dépendre d'une connexion ou d'un contenu personnalisé ? Deuxième question : est-elle suffisamment distincte des autres pages du site pour éviter tout doublon significatif ? Troisième question : vaut-elle la peine d'être conservée à long terme et est-elle susceptible d'être améliorée en permanence ? Ce n'est que si les réponses à ces trois questions sont « oui » que nous devrions envisager de l'ouvrir à l'indexation.
6.2 Quatre catégories de priorités : concentrez vos efforts là où ils comptent le plus
Donnez la priorité à l'indexation : pages d'articles, pages de produits, pages de catégories principales et pages agrégées véritablement spécialisées. Donnez la priorité au noindex : résultats de recherche interne, pages liées aux comptes et aux commandes, archives vides et pagination profonde, pièces jointes et pages générées automatiquement. Donnez la priorité au fichier robots.txt : répertoires backend et système, chemins d'accès à des ressources sans valeur ajoutée. Enfin, ajoutez une couche supplémentaire d'architecture de l'information : grâce àTaxonomie WordPressOrganisez votre contenu de manière plus claire, et les moteurs de recherche seront naturellement plus enclins à accorder plus d'importance aux pages que vous souhaitez promouvoir. Si des anomalies d'indexation semblent être « en cours d'examen », il est également conseillé de suivre d'abord les procédures recommandées.Guide complet des méthodes de récupérationÉliminez les erreurs de configuration. ::contentReference[oaicite:0]{index=0}

Lien vers cet article :https://www.361sale.com/fr/85059L'article est protégé par le droit d'auteur et doit être reproduit avec mention.















![Emoji[wozuimei]-Photonflux.com | Service professionnel de réparation de WordPress, dans le monde entier, réponse rapide](https://www.361sale.com/wp-content/themes/zibll/img/smilies/wozuimei.gif)
![Émoticône [baoquan] - Photon Wave Network | Services professionnels de réparation WordPress, couverture mondiale, réponse rapide](https://www.361sale.com/wp-content/themes/zibll/img/smilies/baoquan.gif)







Pas de commentaires