




Dans le domaine du développement WordPress, le choix d'une solution de stockage de données constitue une décision architecturale fondamentale et cruciale, qui a un impact direct à la fois sur les coûts d'optimisation des performances ultérieurs et sur la complexité de la migration des données.wp_postmetaLe tableau, qui sert de système de gestion des métadonnées intégré à la plateforme, stocke les données d'extension de plus de 90% plugins. Cette approche, associée au tableau de données personnalisé (une solution de stockage conçue de manière indépendante), représente deux philosophies de conception et deux voies techniques fondamentalement distinctes. Les données du secteur indiquent que des choix erronés entraînent un taux de refactorisation en cours de projet de 35%, ce qui augmente les coûts de maintenance moyens de 140 heures-homme.
Comprendre leurs caractéristiques intrinsèques, leurs capacités de performance et leurs limites d'application permet aux développeurs de faire des choix architecturaux judicieux dès le début d'un projet. Cette approche évite l'accumulation d'une dette technique qui pourrait entraîner des difficultés de maintenance par la suite, tout en maintenant les variations d'efficacité des requêtes de données dans une fourchette pouvant aller jusqu'à vingt fois.

I. La distinction entre l'essence architecturale et la philosophie du design
1.1 wp_postmeta : un modèle EAV flexible et axé sur les priorités
WordPresswp_postmetaLe tableau utilise le modèle classique entité-attribut-valeur. Son principe fondamental consiste à traiter la structure des données elle-même comme faisant partie des données à stocker, plutôt que de la fixer lors de la phase de conception de la base de données.
Au niveau de la mise en œuvre technique, chaque enregistrement de métadonnées comprend quatre éléments fondamentaux : un identifiant unique, l'ID de l'article associé, la chaîne de caractères du nom de l'attribut et la valeur correspondante de l'attribut. Toutes les valeurs sont stockées au format texte brut, le système s'appuyant sur la logique au niveau de l'application pour interpréter leurs types spécifiques.
Le principal avantage de cette conception réside dans sa facilité d'extension. Lorsque de nouveaux attributs doivent être ajoutés aux publications, les développeurs n'ont pas besoin de modifier la structure de la base de données ; ils utilisent simplement les nouveaux noms d'attributs dans le code. Cette caractéristique de changement de mode zéro permet aux plugins et aux thèmes d'étendre sans effort le modèle de données de base de WordPress sans opérations de migration complexes.
Le compromis pour la flexibilité est l'absence de sécurité des types. Comme toutes les valeurs sont stockées sous forme textuelle, la base de données ne peut pas appliquer de contraintes de type de données, ce qui transfère entièrement la responsabilité de la validation des données au code de l'application. Cela augmente le risque d'incohérences dans les données et rend les opérations de requête basées sur les valeurs moins efficaces.
1.2 Tableaux de données personnalisés : conception de normalisation axée sur la structure
Les tables de données personnalisées utilisent les méthodologies traditionnelles de conception de bases de données relationnelles. Pendant la phase de conception, les développeurs définissent explicitement la structure de la table, y compris le nom de chaque champ, le type de données, les contraintes et les relations entre les tables.
Le principal avantage de cette conception basée sur un paradigme réside dans l'intégrité et la cohérence des données. Le moteur de base de données effectue des vérifications de type de données, des contraintes de clé étrangère et d'autres validations au niveau du stockage, garantissant ainsi l'exactitude des données. Les champs possèdent une sémantique et des types explicites, ce qui permet à l'optimiseur de requêtes de générer des plans d'exécution efficaces.
La conception de tables personnalisées exige des développeurs qu'ils aient une compréhension claire des structures de données dès les premières étapes d'un projet. Bien que les structures des tables puissent être modifiées ultérieurement par le biais d'opérations de migration, cela s'avère beaucoup plus complexe que le simple ajout d'un nouvel attribut de métadonnées. Cet investissement initial permet d'améliorer considérablement les performances des requêtes et de standardiser la gestion des données dans les étapes ultérieures.
II. Analyse objective de l'efficacité et des performances des requêtes
2.1 Performances dans des scénarios de requêtes simples
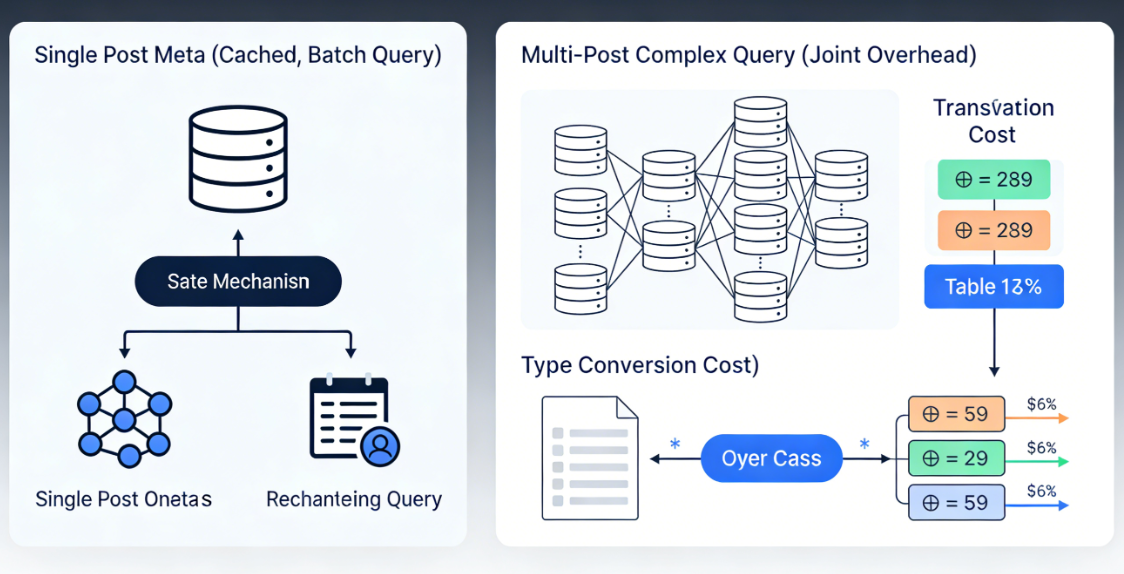
Pour les opérations sur les métadonnées basées sur des articles individuels,wp_postmetaLa table, après avoir été optimisée, est capable de fournir des performances acceptables.WordPressLe mécanisme de mise en cache intégré stocke les métadonnées récemment consultées, réduisant ainsi l'accès direct à la base de données. Lors de la récupération de toutes les métadonnées d'un article, le système exécute une seule requête pour extraire tous les enregistrements pertinents. Cette approche de traitement par lots allège dans une certaine mesure la pression sur les performances.
Cependant, dans les scénarios impliquant plusieurs articles et des critères de filtrage complexes,wp_postmetaLes goulots d'étranglement en termes de performances deviennent évidents. Chaque valeur d'attribut étant stockée dans une ligne distincte, les requêtes basées sur les valeurs d'attributs nécessitent des opérations de jointure ou des sous-requêtes importantes. En particulier lors de requêtes par plage, de tris ou de calculs d'agrégation, la base de données doit convertir les valeurs textuelles en types appropriés, et cette étape supplémentaire augmente considérablement la charge de travail liée aux requêtes.
2.2 Tests comparatifs dans des scénarios de requêtes complexes
Prenons un exemple typique tiré d'un catalogue de produits : la nécessité de rechercher tous les produits appartenant à une gamme de prix spécifique, disponibles en stock et appartenant à une catégorie particulière. À l'aide dewp_postmetaLa solution proposée nécessite au moins trois jointures de tables pour cette requête, chacune basée sur l'ID de l'article et un nom d'attribut spécifique. À mesure que les conditions de filtrage augmentent, la complexité de la requête croît de manière linéaire.
En revanche, l'approche basée sur les tables de données personnalisées stocke tous ces attributs dans différentes colonnes au sein d'une même ligne. Les requêtes peuvent être simplifiées en filtrage conditionnel sur une seule table, la base de données pouvant utiliser des index composites pour accélérer ce processus. Les données de test indiquent que, sur des ensembles de données contenant des dizaines de milliers d'enregistrements, les requêtes utilisant l'approche basée sur les tables personnalisées sont généralement plus performantes.wp_postmetaLa solution est jusqu'à 5 à 20 fois plus rapide, la différence exacte dépendant de la complexité de la requête.
2.3 Considérations relatives aux performances pour les opérations d'écriture
En termes d'écriture des données, les différences entre les deux approches sont tout aussi marquées.wp_postmetaChaque mise à jour implique des opérations indépendantes sur les lignes de données. Lorsqu'un article nécessite des mises à jour importantes des métadonnées, cela génère plusieurs requêtes d'écriture dans la base de données. Bien que WordPress tente de traiter ces opérations par lots, le mécanisme sous-jacent comprend toujours plusieurs insertions ou mises à jour distinctes.
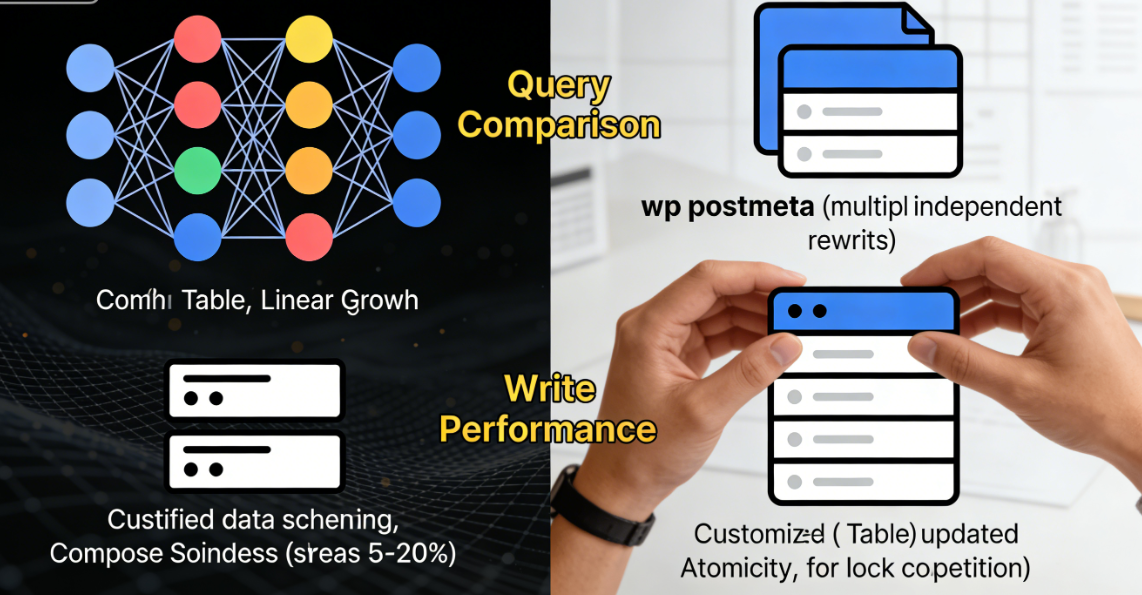
Les mises à jour des tables de données personnalisées sont généralement effectuées dans une seule ligne, le mécanisme de traitement des transactions de la base de données garantissant l'atomicité des mises à jour des champs concernés. Ce modèle à opération unique réduit les conflits de verrouillage de la base de données, offrant une stabilité de performance supérieure dans les scénarios d'écriture à haute concurrence.
III. Évaluation complète de l'évolutivité et de la maintenance à long terme
3.1 La complexité de l'évolution des structures de données
Les exigences des projets évoluent naturellement au fil du temps ; les solutions de stockage des données doivent s'adapter à cette évolution.wp_postmetaLa solution présente des avantages inhérents en matière de gestion des ajouts et des suppressions de champs. L'introduction de nouveaux champs ne nécessite aucune modification du schéma de la base de données ; il suffit simplement de commencer à utiliser les nouveaux noms de propriétés dans le code. Cette flexibilité s'avère très intéressante dans les environnements de développement caractérisés par des itérations rapides.
Cependant, cette flexibilité peut également devenir un fardeau en termes de maintenance. Au fil du temps, différentes versions de plugins peuvent utiliser des noms de propriétés variés pour stocker des données ayant des significations identiques, ou un même nom de propriété peut avoir des connotations différentes selon le contexte. Sans documentation explicite sur le schéma, ces structures de données implicites deviennent difficiles à comprendre et à maintenir.
Les tableaux de données personnalisés nécessitent des modifications structurelles explicites. L'ajout de nouveaux champs nécessite l'exécution deALTER TABLEdéclarationCela nécessite une gestion des changements plus stricte et peut entraîner des temps d'arrêt. Cependant, ces modifications explicites génèrent une documentation architecturale claire, chaque ajout, modification ou suppression d'un champ étant explicitement enregistré. Du point de vue de la maintenance à long terme, cette clarté s'avère souvent plus précieuse que la commodité à court terme.
3.2 Compatibilité avec l'écosystème WordPress
wp_postmetaL'un de ses principaux avantages réside dans son intégration poussée avec les fonctionnalités de base de WordPress. De nombreuses fonctionnalités intégrées, telles que les révisions d'articles, l'enregistrement automatique des brouillons et le mécanisme de récupération de la corbeille, sont étroitement liées au système de métadonnées. L'utilisation de tables de données personnalisées nécessite soit de mettre en œuvre ces intégrations de manière indépendante, soit d'accepter l'absence de certaines fonctionnalités de base.
D'autre part, les tables de données personnalisées offrent une séparation plus claire des limites. Les données commerciales et les données de gestion de contenu sont stockées dans des tables physiques distinctes, une séparation qui rend le modèle de données plus compréhensible et simplifie les stratégies de sauvegarde et de restauration. Dans les scénarios nécessitant une intégration avec des systèmes externes, des limites de données claires réduisent la complexité du couplage.
3.3 Complexités liées à la migration et à la conversion des données
Lorsque le projet passe dewp_postmetaLe principal défi rencontré lors de la migration du schéma vers un schéma de table de données personnalisé estNettoyage des donnéesTransformation des données et des structures. Les tables de métadonnées peuvent contenir des formats incohérents, des enregistrements en double ou des valeurs non valides. Le processus de migration nécessite un traitement minutieux de ces problèmes liés à la qualité des données.
La migration dans le sens inverse est moins complexe, mais peut entraîner une perte partielle d'informations. Les contraintes de type strictes dans les tables personnalisées peuvent entraîner une perte de précision ou d'informations sémantiques lors de la conversion en stockage texte.
IV. Conseils pratiques : un cadre décisionnel basé sur des scénarios
4.1 Clarifier les cas d'utilisation appropriés pour wp_postmeta
Certains types de projets se prêtent mieux à l'adoptionwp_postmetaSchémas. Ces projets présentent généralement les caractéristiques suivantes : structures de données simples et stables, avec un nombre limité d'attributs par entité ; modèles de requêtes centrés sur des entités individuelles, nécessitant rarement des requêtes complexes entre entités ; taille modeste du projet avec des volumes de données limités ; et nécessité d'exploiter pleinement les fonctionnalités intégrées de WordPress, telles que l'historique des révisions et l'enregistrement automatique.
Les cas d'utilisation typiques comprennent les sites Web simples basés sur le contenu, les plateformes de blogs et les pages de présentation promotionnelles. Dans ces scénarios, les exigences en matière de métadonnées pour le contenu sont relativement fixes, les exigences en matière de performances sont modestes et l'efficacité du développement prime sur l'efficacité de l'exécution.
4.2 Identification des caractéristiques du projet nécessitant des tableaux de données personnalisés
Lorsqu'un projet présente les caractéristiques suivantes, il convient d'envisager sérieusement la mise en œuvre d'une solution de table de données personnalisée : - Structures de données complexes avec des entités et des relations commerciales bien définies ; - Exigences de requêtes diverses et complexes impliquant un filtrage à conditions multiples, des calculs d'agrégation ou des opérations de tri ; - Croissance substantielle prévue des données, pouvant atteindre des dizaines de milliers, voire des millions d'enregistrements ; - Nécessité d'échanger ou d'intégrer des données avec des systèmes externes ; - Exigences élevées en matière de performances des requêtes, où les temps de réponse ont un impact direct sur les résultats commerciaux.
Les scénarios d'application typiques comprennent les plateformes de commerce électronique, les systèmes de gestion des adhésions, les systèmes de réservation en ligne et les systèmes de gestion de l'apprentissage. Ces systèmes se caractérisent généralement par des modèles commerciaux bien définis, des relations de données complexes et des exigences de performance strictes.
4.3 L'application judicieuse de stratégies hybrides
Dans les projets pratiques, adopter une solution unique peut ne pas être le choix optimal. Une stratégie hybride permet de sélectionner la méthode de stockage la plus appropriée en fonction des caractéristiques des différents types de données.
Les données de contenu principales peuvent continuer à utiliser les publications standard de WordPress etSystème de métadonnéesMaintenir une compatibilité totale avec les fonctionnalités de la plateforme. Les données structurées spécifiques à l'entreprise sont stockées à l'aide de tableaux de données personnalisés afin d'optimiser les performances et la sécurité des types. Les deux systèmes sont reliés par des identifiants d'articles, ce qui permet d'effectuer des requêtes de corrélation de données lorsque cela est nécessaire.
Cette approche hybride permet d'atteindre un équilibre entre compatibilité et performances, efficacité de développement et efficacité d'exécution. Elle exige une conception architecturale plus méticuleuse, mais offre souvent les meilleurs résultats globaux dans le cadre de projets complexes.

V. Conclusion : l'art de l'équilibre
Le choix d'une solution de stockage de données consiste essentiellement à trouver un équilibre entre différentes exigences.wp_postmetaCette solution offre des avantages en termes d'efficacité de développement, de flexibilité et d'intégration dans l'écosystème, tandis que les tables de données personnalisées démontrent des performances supérieures en matière d'efficacité des requêtes, de cohérence des données et de maintenabilité à long terme.
Il n'y a pas de réponse unique, mais seulement le choix le plus approprié pour un contexte spécifique. Cette décision doit être fondée sur une compréhension approfondie des exigences du projet, une prévision raisonnable des modèles de croissance des données et une évaluation objective des capacités techniques de l'équipe. Les développeurs prudents consacrent du temps à l'analyse architecturale dès les premières étapes du projet, car les choix effectués à ce niveau fondamental auront des implications durables tout au long du cycle de vie du projet.
À mesure que WordPress évolue vers une plateforme d'applications plus complète, le choix de l'architecture de stockage des données devient de plus en plus critique. Qu'il s'agisse d'adhérer au système de métadonnées intégré ou d'introduire des tables de données personnalisées, l'objectif reste de construire une solution fiable, facile à maintenir et capable de répondre aux exigences commerciales. Comprendre les caractéristiques inhérentes à ces deux approches est la première étape vers la prise de décisions techniques éclairées.

Lien vers cet article :https://www.361sale.com/fr/82343L'article est protégé par le droit d'auteur et doit être reproduit avec mention.














![Emoji[wozuimei]-Photonflux.com | Service professionnel de réparation de WordPress, dans le monde entier, réponse rapide](https://www.361sale.com/wp-content/themes/zibll/img/smilies/wozuimei.gif)
![Émoticône [baoquan] - Photon Wave Network | Services professionnels de réparation WordPress, couverture mondiale, réponse rapide](https://www.361sale.com/wp-content/themes/zibll/img/smilies/baoquan.gif)







Pas de commentaires